The headlines about DeepSeek R1’s cost are missing an even bigger story, the R1-Zero model. This model, and research behind it, are reshaping how we thought AI assistants should be trained.
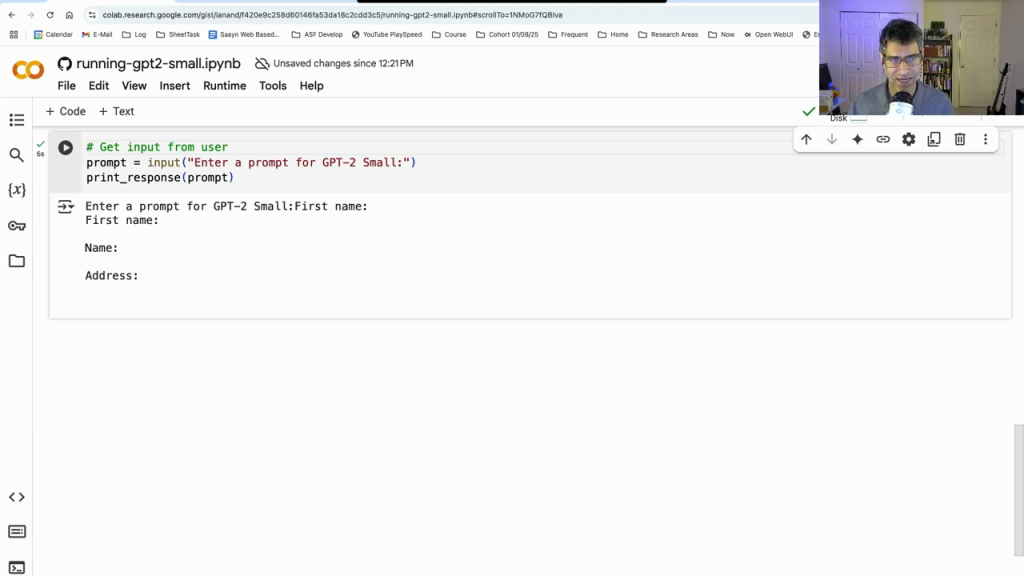
To understand why the R1-Zero model matters, we have to look at how AI chatbots like ChatGPT are typically created. When an AI model is trained on text from the internet, the resulting model is actually pretty dumb. Chatting with it is useless because it only knows how to literally imitate text on the internet. For example, in the video for this blog post, when the model (called a “base model”) is given a prompt like “First Name:”, it replies “Name:, Address:”. Essentially, the model is trying to guess what kind of web page might contain the prompt and then replies with the imagined content from the rest of that hypothetical web page. In this case, it sees “First Name:” and guesses it’s part of a form, so it replies with the rest of the form (i.e. Address). This is effective enough for crafting fake news stories about Unicorns but it can’t carry a conversation nor answer user questions directly.
To turn this “base model” (also known as a “pretrained model”) into a chatbot like ChatGPT has typically involved a complex and labor-intensive process. The process requires the three major steps shown in the diagram below (adapted from the State of GPT) that are labeled “Supervised Finetuning”, “Reward Modeling”, and “Reinforcement Learning”.
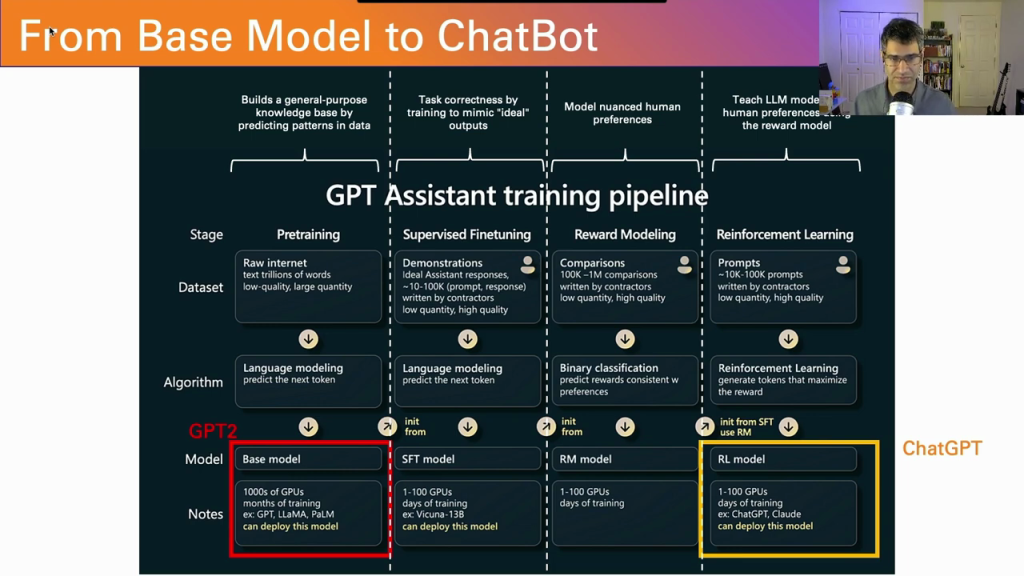
The “Supervised Finetuning” step requires humans to write thousands of example conversations teaching the model how a helpful AI assistant should behave. Even once the model has learned from those examples, humans are needed to grade the quality of the responses the model produces which further fine tunes the quality of the model in a process called “Reinforcement Learning from Human Feedback (RLHF)”.
DeepSeek R1-Zero changes the game by eliminating most of this human work. Instead of requiring armies of people to train and fine-tune the AI, it uses math and coding problems to teach the AI how to think and reason. Because these problems have clear right and wrong answers, computers can automatically check if the AI is correct without any human oversight needed.

“It’s an aha moment, not just for the model, but for the researchers,” notes the DeepSeek team, describing the moment their AI learned to catch its own mistakes and consider different approaches to problems.
This breakthrough could accelerate AI development by removing what experts call the “human bottleneck” (the need for extensive human input in training AI systems). It’s already being recognized as a major advancement, with some experts considering it even more significant than other recent AI developments that have grabbed headlines.
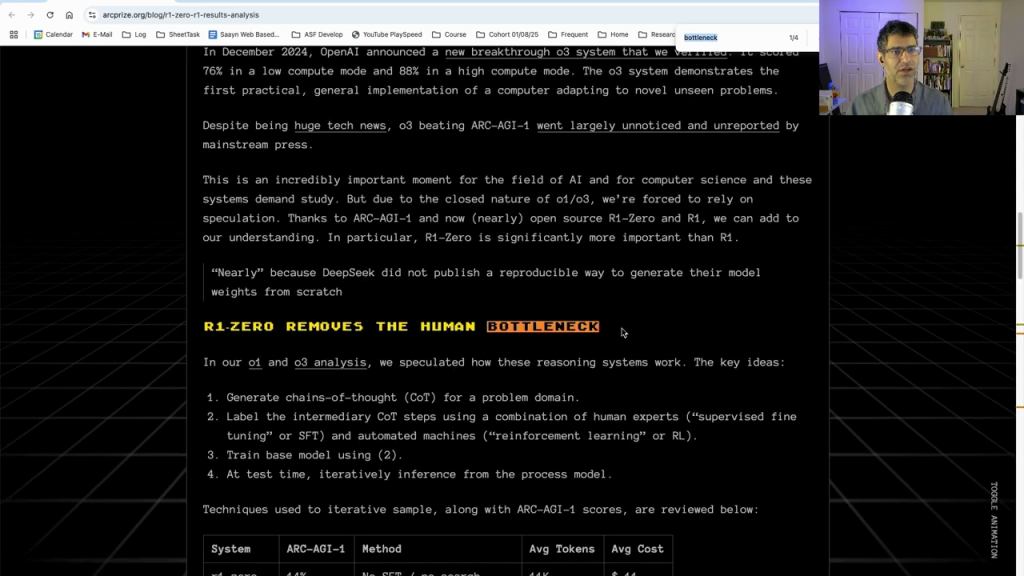
What makes this particularly exciting is that several teams have already successfully reproduced similar results using smaller-scale versions of this approach, suggesting this could become a new standard way of creating AI assistants that can think and reason effectively.
As AI continues to evolve, DeepSeek R1-Zero’s innovative training method might just be the key to creating smarter AI assistants more quickly and efficiently than ever before.